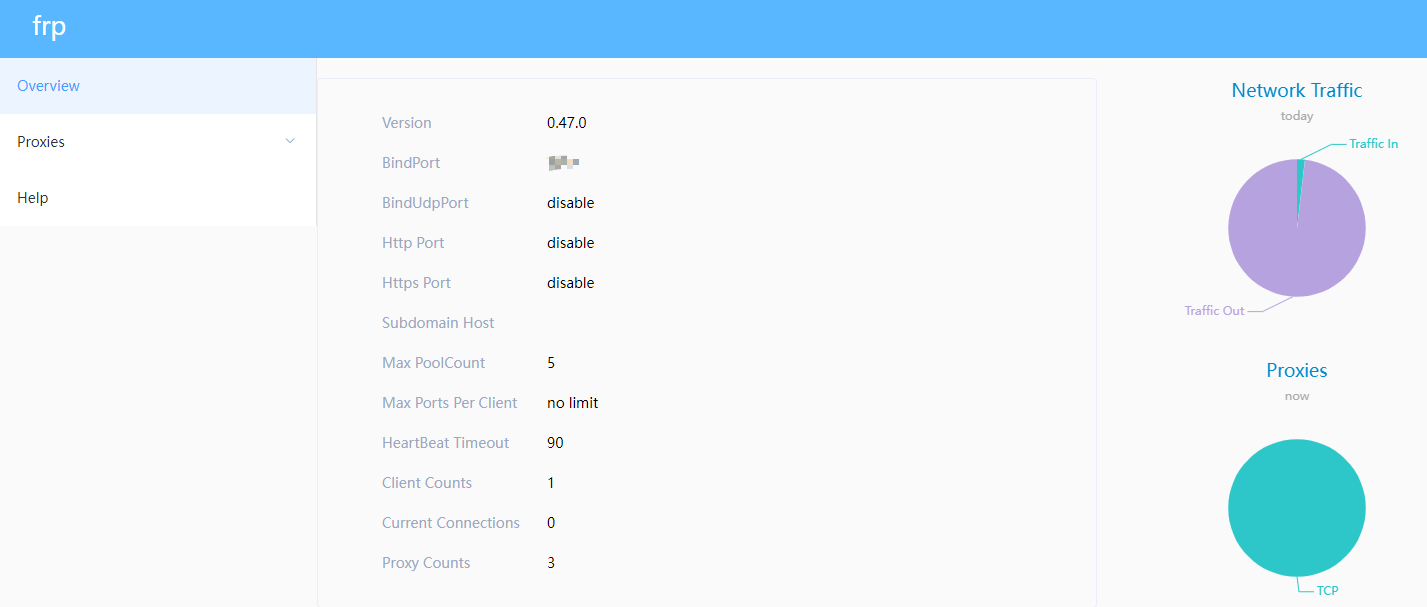
1
2
3
4
5
6
| SpringBootMetadataReader(ObjectMapper objectMapper, RestTemplate restTemplate, String url) throws IOException {
String json = "{\"id\":\"spring-boot\",\"name\":\"Spring Boot\",\"projectReleases\":[{\"version\":\"2.5.0-SNAPSHOT\",\"versionDisplayName\":\"2.5.0-SNAPSHOT\",\"current\":false,\"releaseStatus\":\"SNAPSHOT\",\"snapshot\":true},{\"version\":\"2.5.0-M2\",\"versionDisplayName\":\"2.5.0-M2\",\"current\":false,\"releaseStatus\":\"PRERELEASE\",\"snapshot\":false},{\"version\":\"2.4.4-SNAPSHOT\",\"versionDisplayName\":\"2.4.4-SNAPSHOT\",\"current\":false,\"releaseStatus\":\"SNAPSHOT\",\"snapshot\":true},{\"version\":\"2.4.3\",\"versionDisplayName\":\"2.4.3\",\"current\":true,\"releaseStatus\":\"GENERAL_AVAILABILITY\",\"snapshot\":false},{\"version\":\"2.3.10.BUILD-SNAPSHOT\",\"versionDisplayName\":\"2.3.10.BUILD-SNAPSHOT\",\"current\":false,\"releaseStatus\":\"SNAPSHOT\",\"snapshot\":true},{\"version\":\"2.3.9.RELEASE\",\"versionDisplayName\":\"2.3.9.RELEASE\",\"current\":false,\"releaseStatus\":\"GENERAL_AVAILABILITY\",\"snapshot\":false},{\"version\":\"2.2.13.RELEASE\",\"versionDisplayName\":\"2.2.13.RELEASE\",\"current\":false,\"releaseStatus\":\"GENERAL_AVAILABILITY\",\"snapshot\":false},{\"version\":\"2.1.18.RELEASE\",\"versionDisplayName\":\"2.1.18.RELEASE\",\"current\":false,\"releaseStatus\":\"GENERAL_AVAILABILITY\",\"snapshot\":false}]}";
this.content = objectMapper.readTree(json);
}
|